




Table of contents
AI is changing the world rapidly, from writing a single line of code to generating big projects, from generating a simple message to writing a whole book, creating overwhelming AI art or even management and marketing purposes. AI is now everywhere. AI is not just present, it is the future.
This blog is all about Generative AI's special component: Large Language Models. If you are curious how Large Language Models started, its applications and what will be its future, then you will definitely enjoy reading this blog.
What is Generative AI?
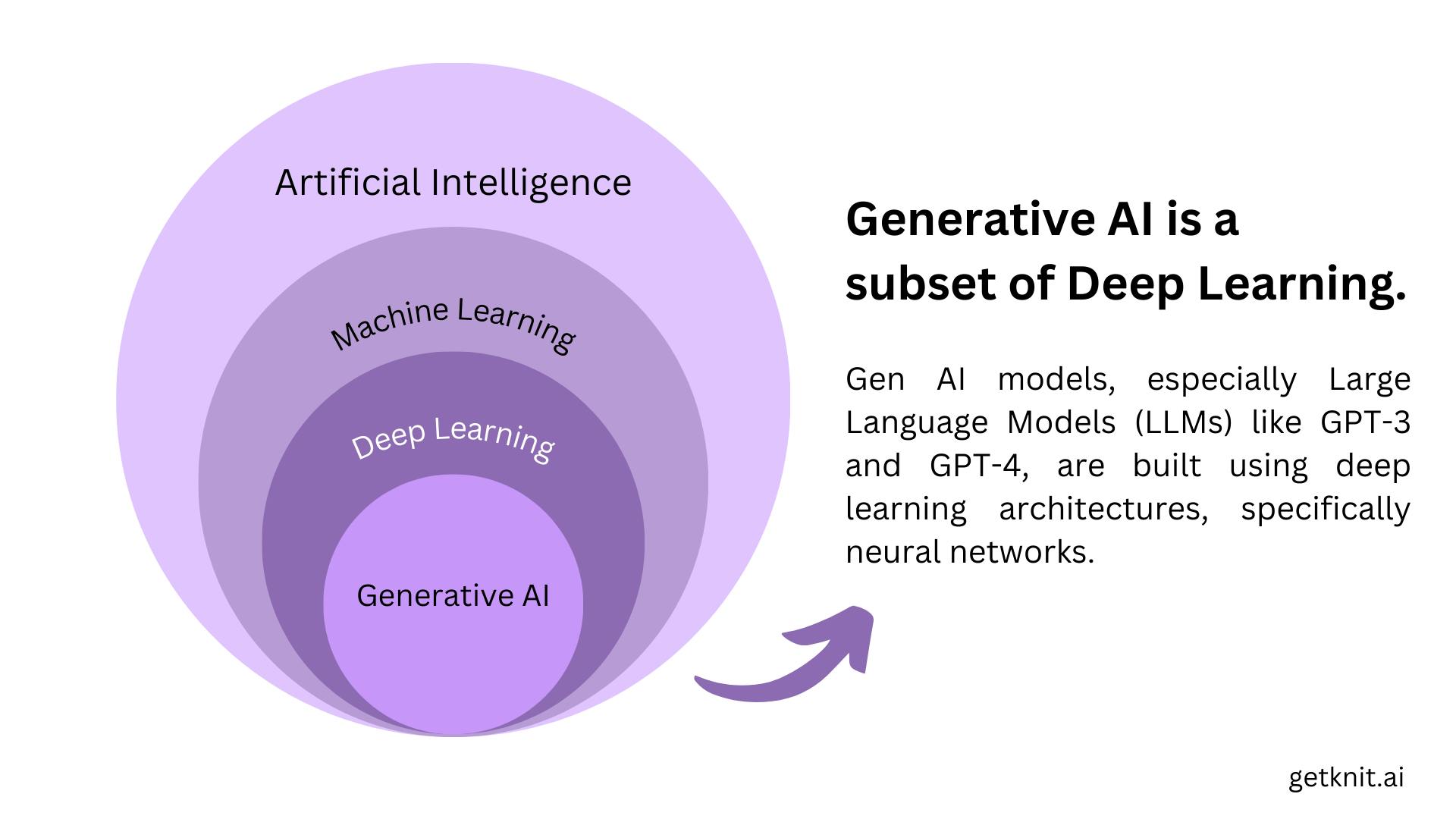
Before going straight to LLMs, we should get a quick intro about Gen AI too. Generative AI is a type of artificial intelligence that involves creating new and original data or content.
Unlike traditional AI models that rely on large datasets and algorithms to classify or predict outcomes, generative AI models are designed to learn the underlying patterns and structure of the data and generate novel outputs that mimic human creativity with the help of neural networks. Inputs and outputs to these models can include text, images, sounds, animation or other types of data.
Generative AI is not just a leap in technology; it's a step towards machines that not only understand us but also speak our language with an eloquence that echoes the depths of human creativity
Now, lets understand one of the special part of Gen AI that is LLMs (Large Language Models).
Deep diving into LLMs
LLMs are advanced AI models designed to process and generate human language by learning patterns and structures from vast amounts of text data.
Suppose you start typing a sentence, and these models predict what you're going to say next.
They are powered by artificial neural networks, which are mathematical models that can learn from data and perform various tasks. Wait, now what are Neural Networks?
Neural networks are inspired by the concept of human brain, they consist of interconnected nodes, or artificial neurons, organized into layers. These layers collaborate to process and analyze data, enabling the network to recognize patterns, make predictions, or perform various tasks.
LLMs have become very popular and influential in recent years but how did they evolve and what are the main milestones in their development? In this blog post, we will dig into complete history of LLMs, learning about each model from its origins to its current applications.
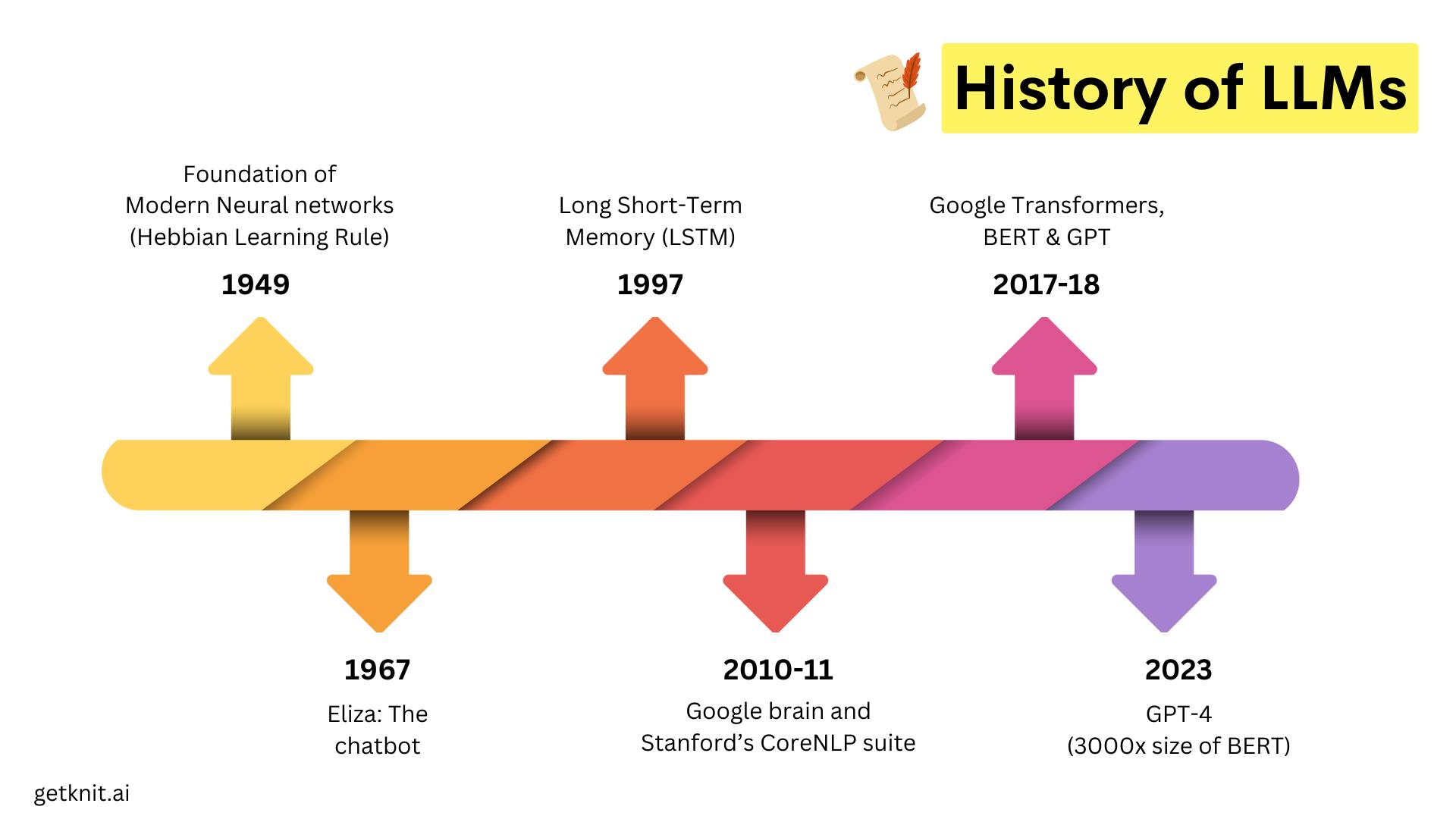
1950s and 60s: When it all started
Back in 1950s, when concept of machines learning on their own was a daring dream, a Canadian psychologist named Donald Hebb introduced Hebbian Rule which laid the foundation of modern Neural Networks.
Researchers started using statistical methods that can help in analysing and generating texts. One of the most common methods was the n-gram model, which is based on the idea that the probability of a word depends on the previous n-1 words.
For example, a 3-gram model (also called a trigram model) would predict the next word based on the previous two words. For instance, given the words "the cat", a 3-gram model might predict that the next word is "is", "was", or "likes", depending on how often these words follow "the cat" in a large collection of texts.
In 1966, MIT professor Joseph Weizenbaum created Eliza. It was a simple chatbot that could interact with users in a typed conversation but it was of great signifance as it showcased the potential for computers to understand and respond to natural language.
1997: RNNs and LSTMs
Recurrent Neural Networks (RNNs) are artificial neural network that are designed to process sequences of data, making them well-suited for tasks involving time series data, voice, natural language, and other sequential activities. They are called “recurrent” because they perform the same task for every element of the input sequence, using the output from the previous step as input for the next.
Long Short-Term Memory (LSTM) is a better version of the recurrent neural network(RNNs), LSTMs are great for figuring out what comes next in a sequence and are super good at understanding long-term patterns. LSTMs became very popular and widely used for various NLP tasks, such as machine translation, text summarization, speech recognition, and text generation.
2017: The breakthrough of attention: Transformers and BERT
The advent of Transformers in 2017 marked a significant milestone in the field of natural language processing (NLP). The Transformer architecture was introduced in the paper titled "Attention is All You Need" by researchers at Google. Below is the image of transformers model.
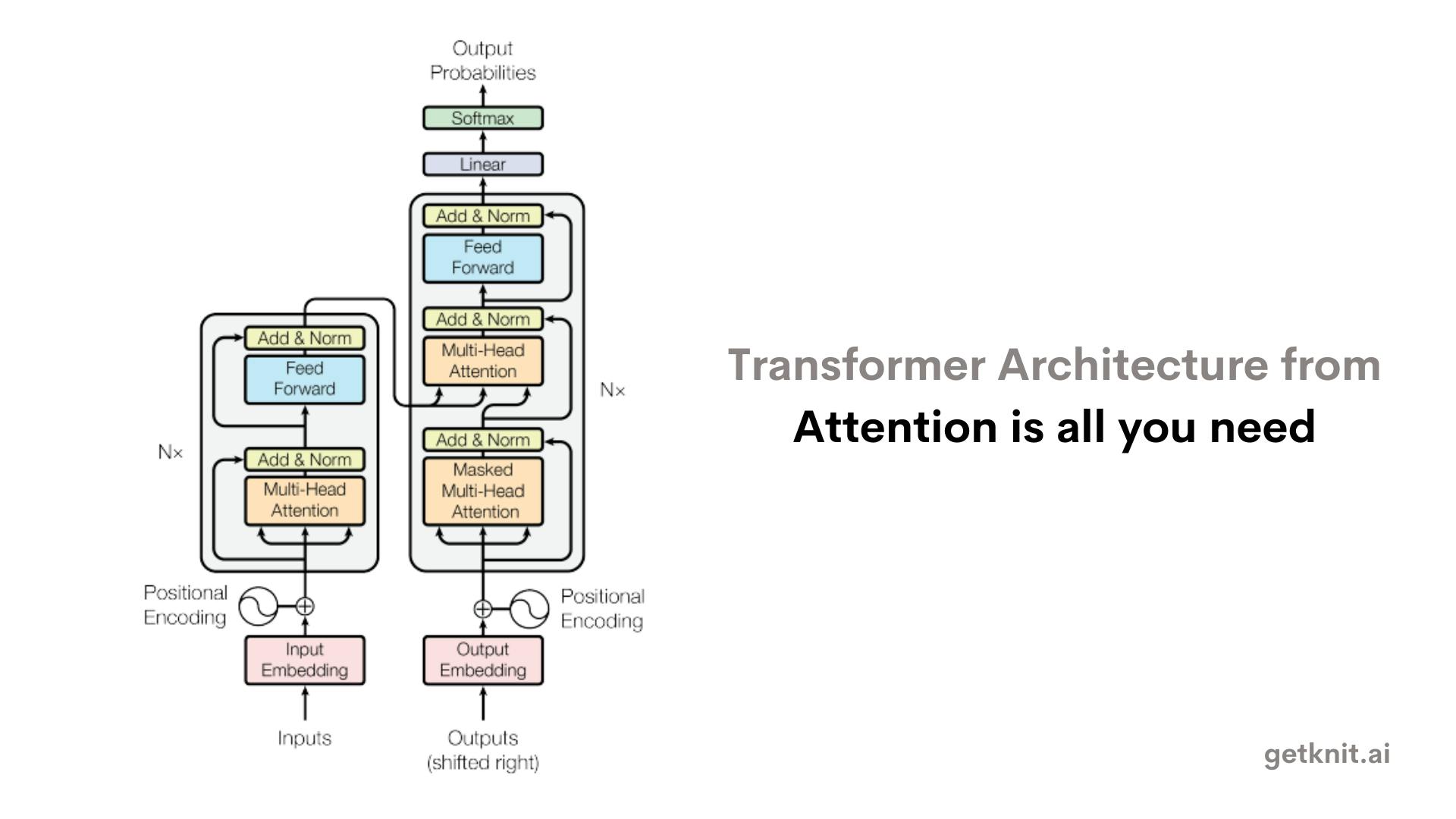
Unlike RNNs and LSTMs, transformers do not process sequential data one word at a time, but rather encode and decode all words in parallel using multiple layers of attention. This makes transformers faster and more powerful than previous models, as they can capture long-term dependencies and complex semantic relationships between words.
One of the most influential applications of transformers for NLP is BERT (Bidirectional Encoder Representations from Transformers).
BERT is a pre-trained model that can learn general language representations from a large corpus of unlabeled texts using two tasks: masked language modeling and next sentence prediction.
i) Masked language modeling involves randomly masking some words in a sentence and asking the model to predict them based on the context.
ii) Next sentence prediction involves asking the model to predict whether two sentences are consecutive or not in a text.
By pre-training BERT on these tasks, researchers were able to obtain a powerful model that can be fine-tuned for various downstream NLP tasks, such as question answering, sentiment analysis, named entity recognition, and text generation.
2018-present : The era of large-scale LLMs: GPT and its successors
In 2018, another milestone was reached in the development of LLMs: the release of GPT (Generative Pre-trained Transformer) by OpenAI, a research organization dedicated to creating and promoting beneficial artificial intelligence.
GPT is a transformer-based model that can generate natural language texts based on a given prompt. GPT is unidirectional, meaning that it only predicts the next word based on the previous words.
However, GPT has a much larger size and vocabulary than BERT, as it was pre-trained on a massive corpus of 40 GB of texts from the internet. GPT can generate coherent and diverse texts on various topics and domains, showing a remarkable ability to mimic human language.
Since then, several successors of GPT have been developed, each increasing the size and performance of the model.
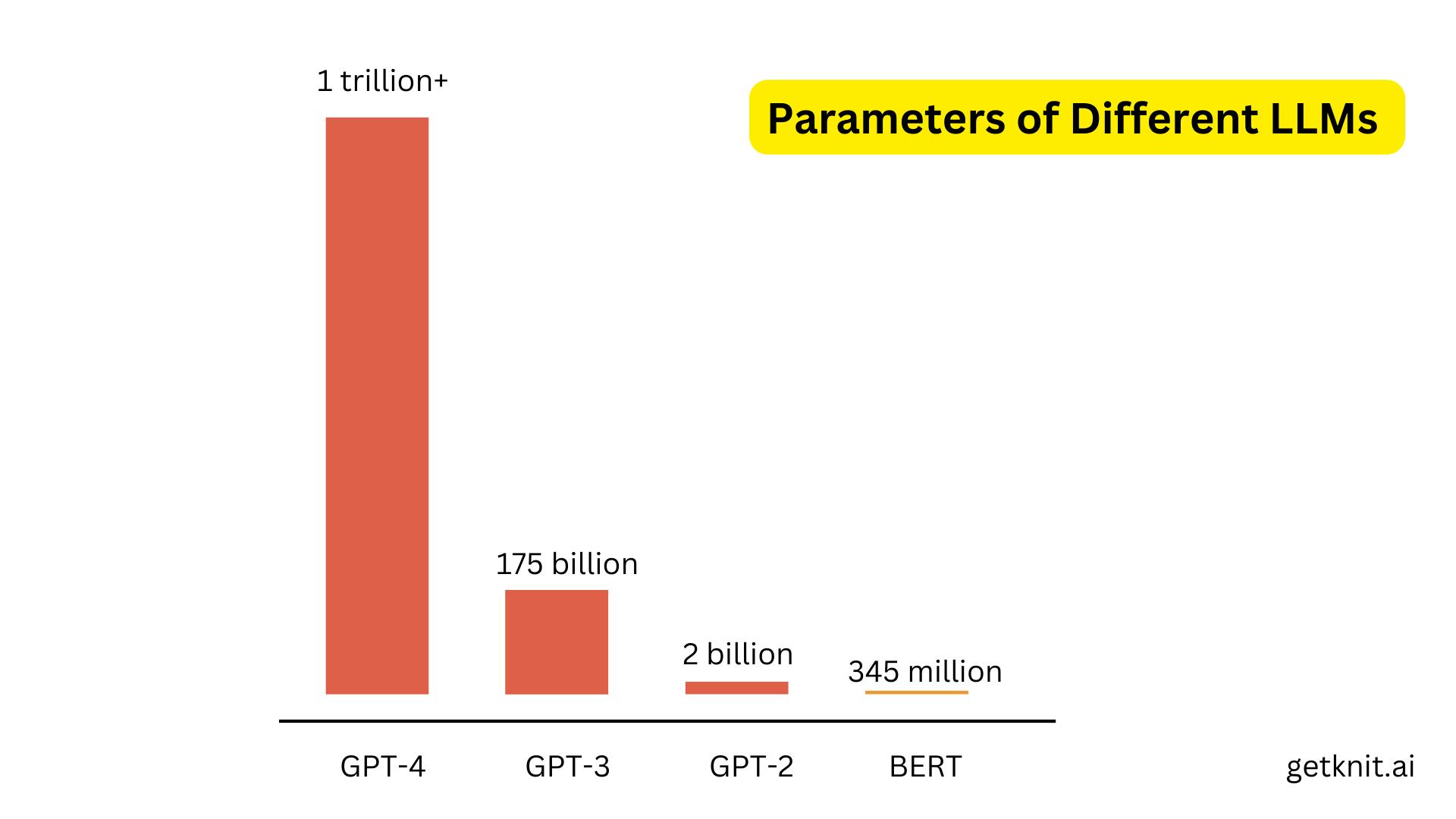
In 2019, OpenAI released GPT-2, which has 1.5 billion parameters (compared to 117 million for GPT) and was pre-trained on a larger corpus of 40 GB of texts from the internet. GPT-2 can generate even more realistic and fluent texts than GPT. OpenAI initially released only a smaller version of GPT-2 (with 345 million parameters) and later released the full model after conducting research on its social impacts and ethical implications.
In 2020, OpenAI released GPT-3, with 175 billion parameters (compared to 1.5 billion for GPT-2) and pre-trained on a massive corpus of 45 TB of texts from the internet. GPT-3 can perform various NLP tasks without any fine-tuning, such as answering questions, writing summaries, composing emails, creating chatbots, and even generating code.
In 2023, OpenAI released GPT-4, which have 1.76 trillion parameters. It was pre-trained on a larger corpus of ~13 trillion tokens from the internet. OpenAI spent 6 months making GPT-4 safer and more aligned. According to OpenAI, It is 82% less likely to respond to requests for disallowed content and 40% more likely to produce factual responses than GPT-3.5 on internal evaluations.
Common Applications of LLMs
LLMs are popular for generating creative and informative text. But wait, there capabilities are not limited with just this. Here are some of the most common applications of LLMs:
Text Generation
Example : ChatGPT, based on OpenAI's GPT-3, can generate human-like responses in natural language.
Code Generation
Example: GitHub Copilot, powered by OpenAI's Codex, helps developers in generating code snippets as they write
Text Summarization
Example: BERTSUM, an extension of BERT, is used for abstractive summarization.
Emotion/Sentiment Analysis
Example: OpenAI's GPT models can analyze sentiment in text. For instance, they can determine whether a user review is positive or negative
Transcription & Translation
Example: Google's Translatotron, leveraging transformer-based models, performs end-to-end speech translation.
The future of LLMs: Challenges and opportunities
LLMs have come a long way since the first n-gram models, and they have shown remarkable progress and potential for natural language generation. However, they also face many challenges and limitations that need to be addressed in the future. Some of these challenges are:
Data quality and quantity: LLMs will only get bigger and better. They are only as good as the data they are trained on, which means that they can inherit biases, errors, or inconsistencies from their training corpora. LLMs can generate texts that are sexist, racist, or offensive, or that contain factual errors or contradictions. Therefore, it is important to ensure that the data used to train LLMs are reliable, diverse, and representative of the intended domain and audience.
Fact-checking: To mitigate issues related to factual inaccuracy, future LLMs might incorporate fact-checking mechanisms. This would involve cross-referencing generated content with reliable sources to ensure the information provided is accurate and up-to-date.
Addressing Bias and Toxicity : The effectiveness of LLMs is currently hindered by concerns surrounding bias, inaccuracy, and toxicity. Future models will likely focus on mitigating these issues to unlock their full potential. This could involve refining training data to reduce bias, implementing mechanisms to filter out toxic content, and developing methods to ensure the accuracy of generated content.
Alright, wrapping it up! The future of those big-brained Large Language Models (LLMs) is looking bright and a bit tricky. We're talking cool opportunities, like making them more reliable with fact-checking and tweaking data to be fairer. But hey, challenges are there too – biases and toxicity are the not-so-great sidekicks. That's all for this blog. See you in the next blog very soon.
If you want to learn more about LLMs and Gen AI, below are some references used while writing this blog. Enjoy reading and keep exploring.
References:
A Survey of Large Language Models
Attention is All You Need.
Understanding LSTMs
On the origin of LLMs